DoqueDBではUnicodeの任意の文字をデータとして扱うことができます。 この記事では文字の取り扱いについて注意すべきことがらをまとめます。
Unicode追加面の文字を扱うことができます
Unicodeの基本多言語面だけでなく、追加面の文字もデータとして操作できます。
Unicodeは当初、あらゆる文字を16ビット (65536種) で表現することを目標としていました。 その後16ビットでは到底足りないことがわかってきたため、16ビットのプレーンを さらに16枚追加し、最初に用意されたプレーンを基本多言語面、 新たに追加されたプレーンを追加面と呼ぶことにしました。
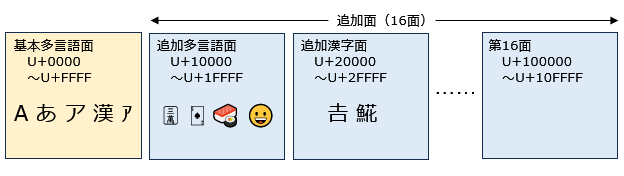
Unicodeの文字はコードポイントと呼ばれる番号で特定されますが、 基本多言語面の文字はコードポイントU+0000~U+FFFF、 追加面の文字はコードポイントU+10000~U+10FFFFで表されます。 追加面の各プレーンにはそれぞれ次のような文字が含まれています。
| プレーン | 文字カテゴリ | 含まれる文字の例 |
|---|---|---|
| 追加多言語面 (U+10000 ~U+1FFFF) |
かな文字補助 | 蕎麦屋の看板などに使われる変体仮名はこの領域にあります。
変体仮名の多くは一般的な日本語フォントでは表示できません。
以下は国立国語研究所による変体仮名一覧表です。 変体仮名一覧表 |
| 麻雀牌 | 🀉 (U+1F009), 🀛 (U+1F01B) | |
| トランプ | 🂡 (U+1F0A1), 🂳 (U+1F0B3) | |
| その他の記号/絵文字 | 🍣 (U+1F363), 🍺 (U+1F37A) | |
| 顔文字 | 😀 (U+1F600), 😡 (U+1F621) | |
| 追加漢字面 (U+20000 ~U+2FFFF) |
CJK統合漢字拡張B | 𠮷 (U+20BB7), 𩸽 (ホッケ, U+29E3D) |
追加面の文字を扱うときは注意が必要です
追加面の文字に関しては、いくつかの操作で期待と異なる結果になることがあります。 その原因と注意事項について説明します。
サロゲートペアとして表現されます
DoqueDBのNVARCHARやNTEXTは、データをUCS2で格納します。 UCS2は16ビット幅であり、基本多言語面の文字は格納できますが、 追加面の文字はそのままでは格納できません。 このため、追加面の文字はサロゲートペアというしくみを使って格納します。 サロゲートペアは上位サロゲートと下位サロゲートという、 2つのUCS2文字を使って1文字を表現するものです (※1) 。 基本多言語面には、上位サロゲートのための領域 (D800~DBFF) と 下位サロゲートのための領域 (DC00~DFFF) が、それぞれ用意されています。 いくつかの文字がUTF8やUCS2でどういう値になるか見てみましょう。
| 文字 | コードポイント | UTF8 (16進) | UCS2 (16進) |
|---|---|---|---|
| A | U+0041 | 41 | 0041 |
| Д | U+0414 | D0 94 | 0414 |
| あ | U+3042 | E3 81 82 | 3042 |
| 漢 | U+6F22 | E6 BC A2 | 6F22 |
| ア | U+FF71 | EF BD B1 | FF71 |
| 🀉 | U+1F009 | F0 9F 80 89 | D83C DC09 |
| 😀 | U+1F600 | F0 9F 98 80 | D83D DE00 |
| 😡 | U+1F621 | F0 9F 98 A1 | D83D DE21 |
| 𠮷 | U+20BB7 | F0 A0 AE B7 | D842 DFB7 |
| 𩸽 | U+29E3D | F0 A9 B8 BD | D867 DE3D |
※1:サロゲートペアは、本来は符号化方式であるUTF16に対して用意されたものです。 UTF16ではサロゲートペアは1文字として扱われます。 内部表現としては同じですが、文字集合であるUCS2では2文字の扱いになります。
格納には2文字分の領域が必要です
「あ」を格納するには長さ1の国際文字列型領域 (NCHAR(1) など) が必要です。 「😀」など追加面の1文字を格納するには長さ2の国際文字列型領域が必要です。 INSERT時に領域より長いデータを渡すと、領域サイズに切り詰められます。
SQL> CREATE TABLE t (col NCHAR(2));
SQL> INSERT INTO t VALUES('😀😀');
{,,ROWID}
{(null),(null),0}
SQL> SELECT * FROM t;
{col}
{😀}
SQL>
長さは2になります
以下のデータが登録されているとします。
CREATE TABLE t (col NVARCHAR(128));
CREATE FULLTEXT INDEX idx ON t(col)
HINT 'INVERTED=(INDEXING=NGRAM, TOKENIZER=NGR:2)';
INSERT INTO t VALUES('A😀C');
INSERT INTO t VALUES('ABC');
INSERT INTO t VALUES('ABBC');
INSERT INTO t VALUES('ABBBC');
INSERT INTO t VALUES('AあC');
INSERT INTO t VALUES('AああC');
INSERT INTO t VALUES('AあああC');
LIKE述語では追加面の1文字が「_」2つとマッチします。
SQL> SELECT * FROM t WHERE col LIKE 'A__C';
{col}
{A😀C}
{ABBC}
{AああC}
SQL>
CHAR_LENGTH関数やSUBSTRING関数でも2文字にカウントされます。 (DoqueDBではSELECTでFROMを省略できないため、 組込み表SYSTEM_SESSIONを参照しています。)
SQL> SELECT CHAR_LENGTH('A😀C') FROM SYSTEM_SESSION;
{char_length('A😀C')}
{4}
SQL> SELECT SUBSTRING('A😀C' FROM 2 FOR 3) FROM SYSTEM_SESSION;
{substring('A😀C' from 2 for 3)}
{😀C}
SQL>
全文索引が設定されているカラムでは、CONTAINS WITHINで近接演算が行えます。 サロゲートペアは近接演算において距離2とカウントされます。 文字「A」と「C」の距離が3という条件で検索すると以下の結果が得られます。
SQL> SELECT * FROM t WHERE col CONTAINS WITHIN('A' 'C' LOWER 3 UPPER 3);
{col}
{A😀C}
{ABBC}
{AああC}
SQL>
誤ったマッチは発生しません
サロゲートペアには以下の性質があり、通常の検索では誤ったマッチは発生しません。
- 上位サロゲートや下位サロゲートは通常の文字とマッチしない
- 上位サロゲートと下位サロゲートはマッチしない
ただし、故意にサロゲートペアを分割すると別の文字とマッチすることがあります。 以下の例では顔文字「😡」の上位サロゲート (D83D) が 別の顔文字「😀」の上位サロゲート (D83D) とマッチしています。
SQL> SELECT * FROM t WHERE col LIKE '%' || SUBSTRING('😀' FROM 1 FOR 1) || '%';
{col}
{A😀C}
SQL> SELECT * FROM t WHERE col LIKE '%' || SUBSTRING('😡' FROM 1 FOR 1) || '%';
{col}
{A😀C}
SQL>
操作により断片になることがあります
サロゲートペアの一方が格納できない場合には断片になることがあります。 サロゲートペアの断片は安全に格納されており、検索にもマッチしますが、 UTF8として表示あるいは出力される際には置換文字 (�, U+FFFD) で置き換えられます。
SQL> CREATE TABLE t (col NCHAR(2));
SQL> INSERT INTO t VALUES('A😀');
{,,ROWID}
{(null),(null),0}
SQL> SELECT * FROM t;
{col}
{A�}
SQL> SELECT * FROM t WHERE col = 'A' || SUBSTRING('😀' FROM 1 FOR 1);
{col}
{A�}
SQL>
また、部分文字列を取得する演算で断片になることがあります。 断片は合成により元に戻ります。
SQL> SELECT SUBSTRING('😀' FROM 1 FOR 1) FROM SYSTEM_SESSION;
{substring('😀' from 1 for 1)}
{�}
SQL> SELECT SUBSTRING('😀' FROM 2 FOR 1) FROM SYSTEM_SESSION;
{substring('😀' from 2 for 1)}
{�}
SQL> SELECT SUBSTRING('😀' FROM 1 FOR 1) || SUBSTRING('😀' FROM 2 FOR 1)
FROM SYSTEM_SESSION;
{substring('😀' from 1 for 1) || substring('😀' from 2 for 1)}
{😀}
SQL>
全文検索において検索語を含む部分文字列を返すKWIC (KeyWord In Context) 関数では、 切り出す部分文字列の開始位置または終了位置で サロゲートペアの断片が生成されることがあります。
SQL> CREATE TABLE t (col NVARCHAR(128));
SQL> CREATE FULLTEXT INDEX idx ON t(col)
HINT 'KWIC, INVERTED=(INDEXING=NGRAM, TOKENIZER=NGR:2)';
SQL> INSERT INTO t VALUES('A😀B😀C');
{,,ROWID}
{(null),(null),0}
SQL> SELECT KWIC(col FOR 1) FROM t WHERE col CONTAINS('B');
{kwic(col for 1)}
{B}
SQL> SELECT KWIC(col FOR 2) FROM t WHERE col CONTAINS('B');
{kwic(col for 2)}
{�B}
SQL> SELECT KWIC(col FOR 3) FROM t WHERE col CONTAINS('B');
{kwic(col for 3)}
{B😀}
SQL> SELECT KWIC(col FOR 4) FROM t WHERE col CONTAINS('B');
{kwic(col for 4)}
{😀B😀}
SQL> SELECT KWIC(col FOR 5) FROM t WHERE col CONTAINS('B');
{kwic(col for 5)}
{😀B😀}
SQL> SELECT KWIC(col FOR 6) FROM t WHERE col CONTAINS('B');
{kwic(col for 6)}
{A😀B😀}
SQL> SELECT KWIC(col FOR 7) FROM t WHERE col CONTAINS('B');
{kwic(col for 7)}
{A😀B😀C}
SQL>
断片も文字コード順にソートされます
サロゲートペアのソート順はUCS2値の順になります。 断片についても同様です。 以下のデータが登録されているとします。
CREATE TABLE t (col NVARCHAR(128));
INSERT INTO t VALUES('🀉:サロゲートペアはD83C DC09');
INSERT INTO t VALUES('😀:サロゲートペアはD83D DE00');
INSERT INTO t VALUES('𠮷:サロゲートペアはD842 DFB7');
INSERT INTO t VALUES('𩸽:サロゲートペアはD867 DE3D');
ORDER BYの結果は以下のようになります。
SQL> SELECT * FROM t ORDER BY col;
{col}
{🀉:サロゲートペアはD83C DC09}
{😀:サロゲートペアはD83D DE00}
{𠮷:サロゲートペアはD842 DFB7}
{𩸽:サロゲートペアはD867 DE3D}
SQL> SELECT * FROM t ORDER BY SUBSTRING(col FROM 2 FOR 1);
{col}
{🀉:サロゲートペアはD83C DC09}
{😀:サロゲートペアはD83D DE00}
{𩸽:サロゲートペアはD867 DE3D}
{𠮷:サロゲートペアはD842 DFB7}
SQL>
おわりに
Unicode追加面の文字を扱うときの注意事項と、具体的な操作結果をご覧いただきました。 追加面の文字は扱い方によっては期待と異なる結果になることがありますが、 結果は予測可能であり、かつさまざまな操作に対して安全です。 仕様を十分ご理解いただいたうえでお取り扱いくださるようお願いします。