全文検索とは
「検索対象文書の本文から特定の文字列を探し出す」ことを、一般に全文検索と呼びます。たとえば図書館で図書を探すとき、通常は書名や著者名、刊行年を指定して探すことになりますが、本文に何らかの文字列が含まれる図書を探す、というのが全文検索です。全文検索は便利な機能ですが、これを行うには、本文そのものをデータとして登録し、検索できるようにしておく必要があります。
全文検索は、大量の情報に囲まれて暮らしている現在の私たちにとっては、仕事のうえでも個人の生活においても、欠くことのできない技術となりました。全文検索のしくみについて、わかりやすく説明していくことにしましょう。
索引を作るか作らないか
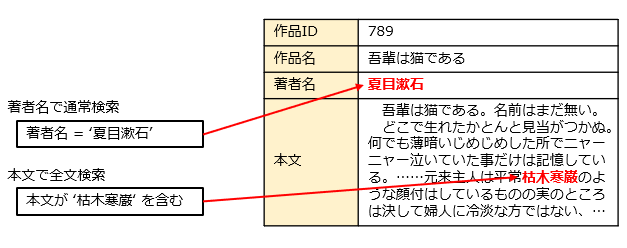
本文中に出てくる単語が、本文のどこにあるかを示す情報を索引と言います。取扱説明書なら巻末に索引があり、特定のキーワードがどのページに出てくるかがわかります。全文検索では、どんな文字列が検索されるかをあらかじめ知ることができないので、本文に出てくるすべての単語の出現位置を示した索引を作っておく必要があります。
ただ、全文検索には必ずしも索引は必要ではありません。特定の単語を探したいなら、本文先頭からしらみつぶしに探していけばよいわけです。時間はかかりますが、あらかじめ索引を作る必要もなく、実現するのも簡単です。このような検索のしかたを、ソフト開発者向けに作られたOSであるUNIXのツールにならってgrep(グレップ)型と呼ぶことがあります。
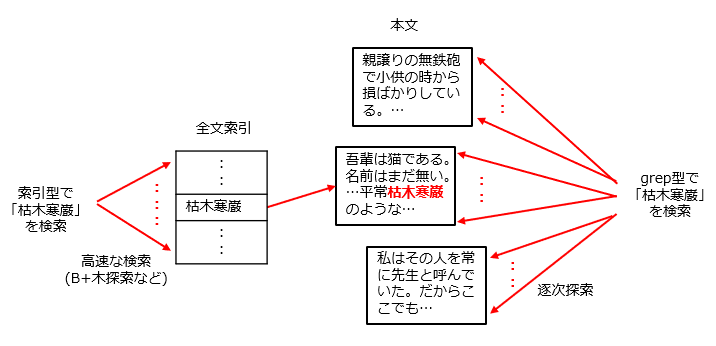
grep型の全文検索は簡単ですが、性能の問題から一般的なアプリでは使われていません。以降では、索引を使った全文検索について説明していくことにしましょう。
全文索引と検索のしくみ
索引を使った全文検索では、あらかじめ文書の登録時に索引を作ります。全文検索に使われる索引を全文索引と呼びます。全文索引には、主な実現方法として形態素解析方式とN-Gram方式があります。どちらの方式を使うにしても、文書の登録時に索引語を切り出すのと同様に、検索時にも検索語を切り出す必要があります。
では、2つの方式についてざっと眺めてみましょう。
形態素解析方式
最初から難しい用語が出てきましたが、形態素とは「文の構成要素でこれ以上分割できないもの」のことです。たとえば人の苗字である「佐藤」なども形態素ですね。
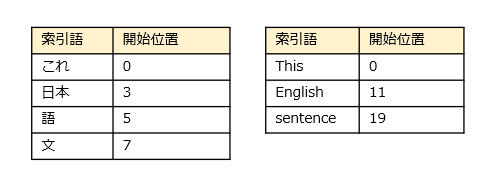
形態素解析方式では、文書の本文を形態素に分割して索引語を作ります。英語なら文章を空白で分割します。日本語では文章の先頭から辞書引きしながら形態素を切り出します。結果は、たとえば次のようになります。

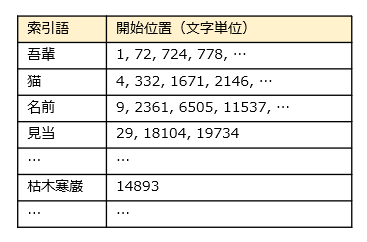
形態素のうち、英語のa, theや日本語の付属語(助動詞や助詞)、記号など、一般的すぎて検索の役に立たない語を除きます。このような語をストップワードと呼びます。こうして残った以下の要素が索引語となります。それぞれの索引語には、どの文書に含まれているかという情報とともに文書内での開始位置が紐づけられています。
検索時には、検索テキストを同様に形態素解析します。検索テキストがただ1つの形態素からなる場合は簡単です。たとえば「日本」なら、「日本」を含む文書を検索して、それで終わりです。
検索テキストが複数の形態素を含む場合はもう少し複雑です。たとえば「日本語の文」を検索した場合、[日本] [語] [の] [文] が形態素として切り出され、ストップワードを除く [日本] [語] [文] をすべて含む文書が検索されます。その後、検索テキスト「日本語の文」が実際に対象文書に含まれているかチェックされ、含まれているときに限り、真の検索結果となります。
N-Gram方式
N-Gram (エヌグラム)とは、「テキストを構成するN文字の断片」のことです。N-Gram方式では、文書内の任意の位置から連続したN文字を切り出して索引語とします。日本語の全文検索では、2文字を単位とするBigram(バイグラム)方式がよく使われます。
たとえば文字列「メロンパン」を含む文書として、Wikipedia日本語版の項目「菠蘿包」の本文冒頭を登録してみましょう。
菠蘿包(ポーローパーウ、boh loh baau)は、香港のパンの一種。
パン生地の上にクッキー生地を被せて焼くのが特徴である。クッキー生地に十字の模様を入れる作り方が日本のメロンパンと共通している。メロンパンと比較すると平均的に直径がやや小さく、高さは高めで、クッキー生地をしっかりと焼き上げているため、さらにサクサクとした食感をしている。メロンパンと違い、クッキー生地の上に砂糖の粒をまぶす作り方はしない。
これにより、次のような索引語が作られます。それぞれの索引語には文書内での開始位置が紐づけられています。
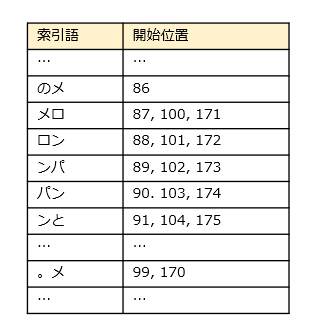
この文書に対し、検索テキスト「メロンパン」を検索してみましょう。2文字ごとに切り分けて、以下の検索語を作ります。最後の[ン] は半端なので、直前の文字と合わせて [パン] とします。0や+2はお互いの位置関係を示しています。
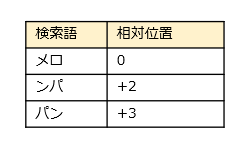
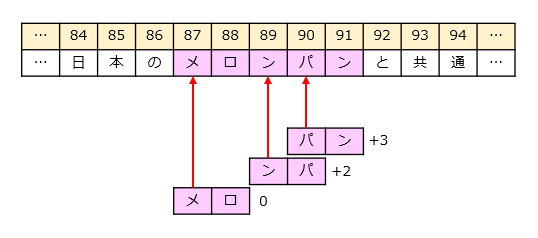
各検索語は元の文書の以下の位置で見つかりました。位置関係も正しいので、「メロンパン」が見つかったことがわかります。
長所と短所
形態素解析方式とN-Gram方式にはそれぞれ長所と短所があります。
形態素解析方式は、長い単語もそのまま索引語として登録されているため、検索がシンプルになり、高速に検索できます。単語の断片が索引語にマッチしないため、ノイズは少なくなります。そのかわり、辞書に登録されていない単語は見つけることができません。(たとえば「京都」で「東京都」は検索できません。)また、索引の作成にはN-Gram方式より時間がかかる傾向があります。
N-Gram方式では、長い単語を検索するのに時間がかかります。単語をN-Gramに分割し、すべての要素を検索したうえで、位置を突き合わせる必要があるためです。また、検索テキストは部分文字列としてマッチするだけなので、ノイズは多くなります。(たとえば「トリック」を検索すると「マトリックス」も見つかります。)逆にいえば、文字列として一致しさえすれば、どんな文字列でも検索できます。つまり、検索の自由度は高いといってよいでしょう。
どちらの方式でも、本来は索引語より短い語は検索できませんが、システムによっては前方一致検索が可能なことがあります。このようなシステムでは、たとえば「東」で「東京」や「東京都」が見つかります。したがって、N-Gram方式では任意の1文字で検索できます。形態素解析方式では、索引語の途中から始まる部分文字列は見つけることができません。
形態素解析方式とN-Gram方式の違いをまとめておきましょう。
| 特徴 | 形態素解析方式 | N-Gram方式 |
|---|---|---|
| 検索速度 | 速い | 形態素解析より時間がかかる |
| ノイズ | 少ない | 多い |
| 辞書にない語 | 見つけられない | 見つけられる |
| 検索の自由度 | 低い | 高い |
| 1文字の検索 | 単語途中からは不可 | システムによっては可 |
デュアル検索
日本語を検索するときN-Gram方式は便利ですが、英単語や数字列は単語単位でマッチしてほしいこともよくあります。
DoqueDBでは索引作成時のヒント句にDUALを指定することにより、英数字は単語単位、日本語はN-Gramで検索することが可能です。これは文字種の境界を示す情報を索引にもつことにより実現しています。
表記ゆれを同一視する
全文検索に限らず、検索全般について言えることですが、検索する文字列の表記上の違いを同一視したいことがよくあります。たとえば英字の大文字と小文字、英数字カナの全角と半角などがこれにあたります。多くの検索システムでは、索引作成時および検索時に入力を正規化することで、このような同一視を実現しています。以下は正規化を用いた検索の例です。
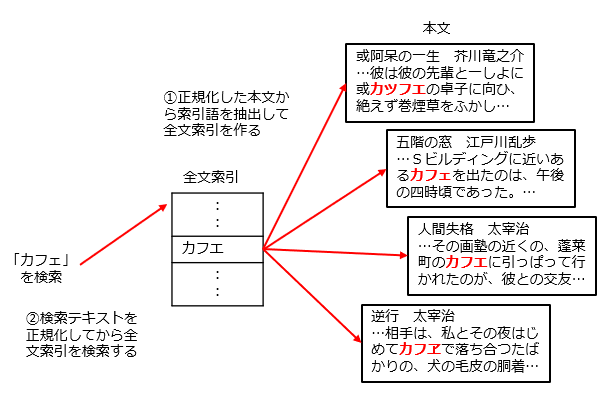
日本語の検索では、文字単位の同一視だけでなく、外来語の表記ゆれ(「インタフェース」と「インターフェイス」)、送り仮名の表記ゆれ(「組み込み」と「組込」)、同義語(「注文」と「オーダー」)などを同一視したいことがあります。DoqueDBでは標準で外来語の表記ゆれに対応しているほか、ユーザー辞書を活用することで送り仮名の表記ゆれや同義語を同一視することが可能です。オープンソースの同義語辞書として、たとえばSudachi同義語辞書が使えます。
DoqueDBで同一視できる表記ゆれを以下にまとめておきましょう。
| 種別 | 例 |
|---|---|
| 英数字記号カナの半角・全角 | ABC⇔ABC, 123⇔123, アイウ⇔アイウ |
| 英字の大文字・小文字 | ABCDE⇔abcde |
| キリル文字の大文字・小文字 | АВГДЕ⇔авгде |
| 漢字の新字体・旧字体 | 檜⇔桧, 龍⇔竜 |
| 外来語の表記ゆれ | インタフェース⇔インターフェイス |
| カナ長音と混同される文字 (マイナス、ハイフンなど) |
ワールド⇔ワ‐ルド |
| 送り仮名の表記ゆれ ※1 | 組み込み⇔組込 |
| 同義語・類語 ※1 | 注文⇔オーダー |
※1 ユーザー辞書を作成することで利用可
全文検索にまつわるいろいろ
全文検索の周辺には理解しておくと役立つ知識がいくつかあります。ここではそれらをいくつか拾って解説しておきましょう。
全文検索エンジンとデータベースの違い
高度な全文検索機能を提供するアプリケーションとしては、Elasticsearchなどのいわゆる全文検索エンジンと、全文検索機能をもつデータベース管理システムがあります。これらは用途によって使い分けるのがよいでしょう。
全文検索エンジンは、大規模なデータを高速に検索することに特化しており、データの追加や更新に比べて検索の頻度が格段に高い用途に向いています。そのかわり、一般的に登録したデータが全文検索できるようになるまでタイムラグがあることに注意が必要です。
データベース管理システムは格納されるデータの一貫性を重視しており、登録されたデータは即時に全文検索が可能です。データの追加や更新が頻繁に発生する用途に向いていますが、全文索引の管理はより複雑なものになります。
| 観点 | 全文検索エンジン | データベース |
|---|---|---|
| 用途 | 検索の頻度が高い用途に向いている | 追加・更新が頻繁に発生する用途に 向いている |
| データ登録 | 登録されたデータが検索できるまで タイムラグがある |
登録されたデータは即時に検索可能 |
| 索引の管理 | 高速な検索に特化しており、頻繁な 更新には不向き |
追加・更新が行いやすいが、データ 構造は複雑になる |
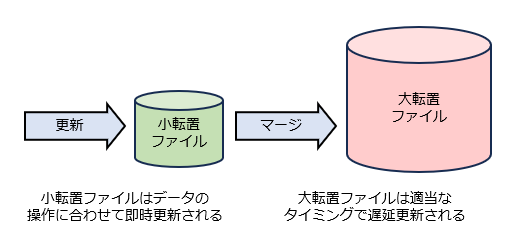
DoqueDBの全文索引は、データの更新がただちに反映される小転置ファイルとすべての索引データをもつ大転置ファイルの二段構えになっています。小転置ファイルの内容は適当なタイミングで大転置ファイルにマージされ、その後小転置ファイルは空になります。このような仕組みにより、高速な更新と大規模データの管理を両立させているわけです。マージの処理中も、データの一貫性は維持されています。
類似文書検索
全文検索の応用のひとつに類似文書検索があります。類似文書検索とは、「テキストを渡してテキストを検索する」ことです。結果はテキストどうしの類似度の順に並べ替えることができます。類似文書検索は関連文書検索、概念検索と呼ばれることもあります。類似文書検索を実現するにあたって、2つの重要な要素があります。1つは検索語の抽出、もう1つはスコア計算です。
検索時に渡したテキストは、そのままでは検索できません。テキストを単語に分割し、実際に検索に使われる単語を決定します。そのためには、「TF-IDF」などのアルゴリズムが使われます。これは、「文書内に頻出する語は重要度が高い (Term Frequency)」、「多くの文書に登場する語は重要度が低い (Inverse Document Frequency)」を掛け合わせたもので、その単語のトータルでの重要度を示すことになります。
単純な全文検索では、検索語は見つかったか見つからなかったかの二者択一ですが、類似文書検索では検索語ごとの重みづけ、スコアへの寄与度が設定され、見つかった検索語からトータルのスコアが求められます。簡単な話に聞こえますが、人間から見たときの類似度と計算されたスコアをできるだけ一致させるために、内部ではさまざまな観点から調整が行われています。
検索語近傍の表示
全文検索の不便な点は、見つかった文書のどこに検索語があるかがわかりづらいところです。この問題に対処するため、全文検索を提供するソフトウェアでは、見つかった文書のうち検索語の近傍を切り出して表示する仕組みをもっています。検索語を含む文書の断片はスニペットあるいは KWIC (KeyWord In Context) と呼ばれ、検索語は何らかの方法でハイライト表示されます。
検索語近傍の表示は、明示的に指定した検索語について行われるのが一般的ですが、DoqueDBでは、類似文書検索においても抽出された検索語近傍の表示が可能です。
SQL> select docid, title, lastname, firstname,
kwic(content for 20 enclose with '/')
from aozorabunko
where content contains('空前絶後')
order by score(content) desc limit 5;
{docid,title,lastname,firstname,kwic(content for 20 enclose with '/')}
{1154,最終戦争論,石原,莞爾,ます。今は人類の歴史で/空前絶後/の重大な時期で}
{2145,鼻の表現,夢野,久作,これ等はすべて、この/空前絶後/の鼻の裁判開始}
{46699,道成寺不見記,夢野,久作,ものである。むしろ/空前絶後/と言いたいくらい}
{46711,ビール会社征伐,夢野,久作,湧き返るという、/空前絶後/の不可思議な盛況}
{55072,乾山の陶器,北大路,魯山人,優美な意匠において、/空前絶後/の腕前を発揮し}
SQL> select docid, title, lastname, firstname,
kwic(content for 20 enclose with '/')
from aozorabunko
where content contains freetext(
'船が難破し無人島に漂着した少年たちが島で生き延びて生還する')
order by score(content) desc limit 5;
{docid,title,lastname,firstname,kwic(content for 20 enclose with '/')}
{1323,海島冒険奇譚 海底軍艦,押川,春浪, 第六回 星火榴彈 /難破//船/の信號――イヤ}
{42767,無人島に生きる十六人,須川,邦彦,/無人島/に/生き/る十六人 須川邦彦 1 中川}
{57532,新宝島,江戸川,乱歩,ひとりでしゃべって、/少年たち/が何も答えない}
{46488,少年連盟,佐藤,紅緑,そこで、/船/室にひそんでいた十一人の/少年たち/を}
{46411,沈黙の水平線,牧,逸馬,かけた/船/は一隻もないのである。/難破//船/らしい}
SQL>
おわりに
全文検索について、さまざまな観点から解説してきましたが、全体的なイメージをつかんでいただけたでしょうか?
何らかの検索を行うアプリケーションやシステムでは、全文検索機能を提供することでユーザーの利便性が大きく向上します。そのためにDoqueDBをお役立ていただけることを祈っています。